Deconfirmed
April 9th, 2009Bug reports in bugzilla.mozilla.org can now be changed back to UNCONFIRMED. Sweet! I'll use this next time I accidentally file a bug that lacks a reduced testcase a "NEW".
(From one of the three long threads on mozilla.dev.planning about Bugzilla statuses and workflow.)
CSS grammar fuzzer
March 16th, 2009I wrote a CSS grammar fuzzer to test Gecko's CSS parser. This fuzzer's tricks:
Declarative context-free grammar. This makes it easy to add new CSS features to the fuzzer, or even use it to test grammars other than CSS. Each symbol can be a star, concatenation, or list of alternatives. Unlike a parser, a fuzzer has to make decisions about what to create, so alternatives can be given weights and stars have a suggested number of repetitions. This alone was enough to find at least one bug in Gecko.
Breaking rules. Like any good fuzzer, it doesn't always follow the given context-free grammar. Sometimes it does weird stuff, such as inserting a random symbol, to throw the parser off. I was surprised that this only found one additional bug in Gecko. Perhaps this reflects the comprehensive error handling requirements of the CSS specifications and the corresponding test suites.
Grammatical recursion. When the fuzzer notices that a symbol is the same as an ancestor, it can repeat the parts of the final string between the two symbols. This is effective at finding bugs where large input can cause a recursive algorithm to run out of stack space and crash. This found four grammar-recursion crashes in Gecko.
CSS serialization. The fuzzer makes sure that any text that comes out of the browser's stylesheet serializer survives another trip through the parser and serializer. This is the same trick jsfunfuzz uses to test the JavaScript engine decompiler. This helped fine four incorrect-serialization bugs in Gecko.
None of these Gecko bugs seem to be security holes. I shared the fuzzer with other browser vendors privately for over a month, and nobody asked me to delay the release, so I believe it didn't find security holes in other browsers either. But I think this has more to do with CSS parsing being fairly simple and self-contained than any weakness in the fuzzer.
After CanSecWest, I'm going to try using this fuzzer to generate JavaScript expressions that crash parsers that use recursion incautiously. Unless someone beats me to it, of course ;) (jsfunfuzz already creates many types of weird JavaScript, but can't look for grammatical recursion opportunities easily because it is written in a functional style rather than a declarative style.)
This fuzzer is written in JavaScript and is MIT licensed. I'd love to hear what other people manage to do with it. Get it here.
Inbox: Zeroed
March 6th, 2009Took me three weeks to clean up five years of email, but I feel victorious.
I was hoping Gmail would congratulate me, but instead, it offers to send me to Google Reader. That's not really what I want staring at me every time I successfully process my email inbox. Who wants to write a Greasemonkey script to fix this for me?
{kind=link}
TidyBug
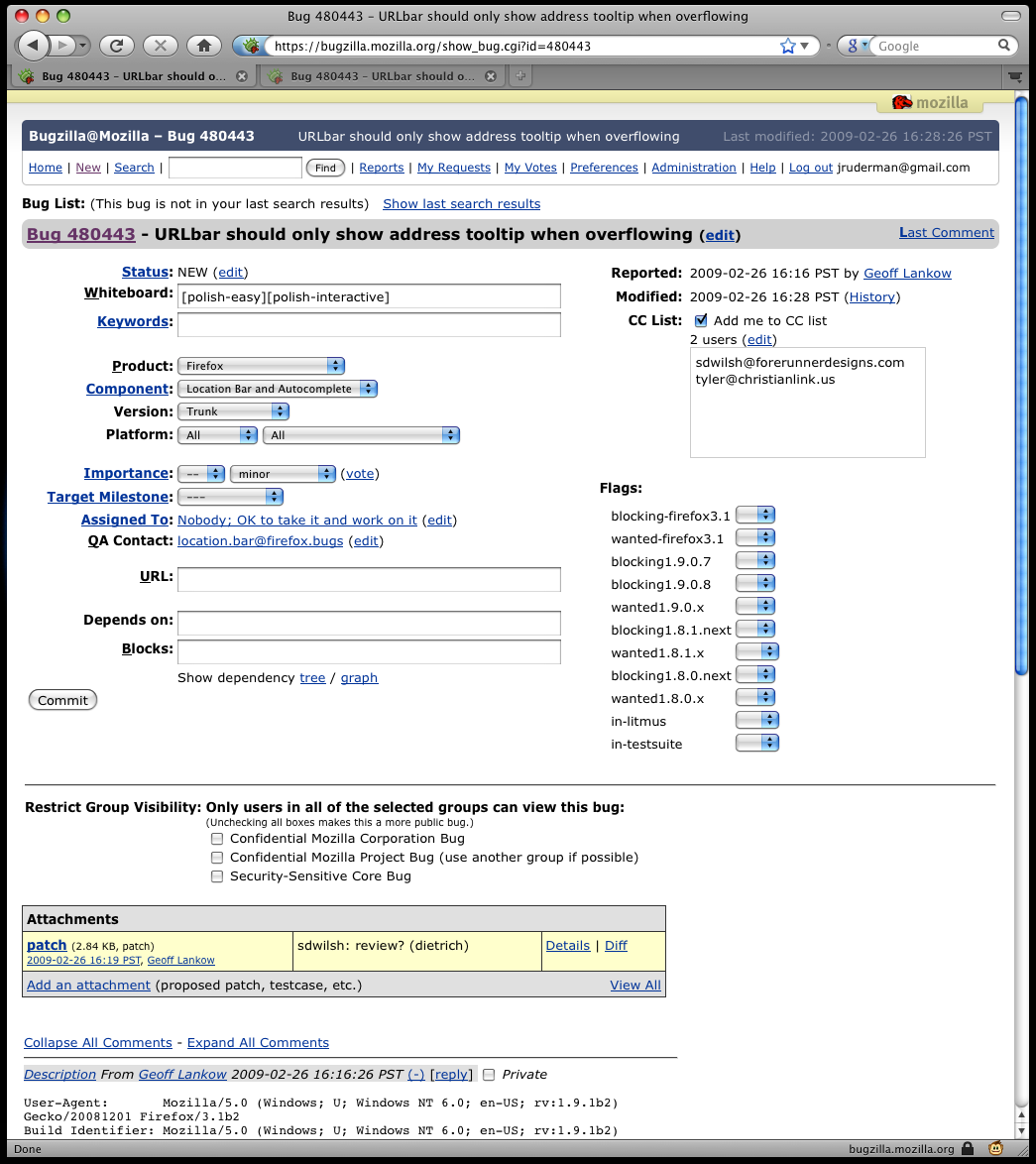
February 26th, 2009My newest Greasemonkey script, TidyBug, cleans up the show-bug page on bugzilla.mozilla.org.
- Old and busted: Bugzilla screenshot
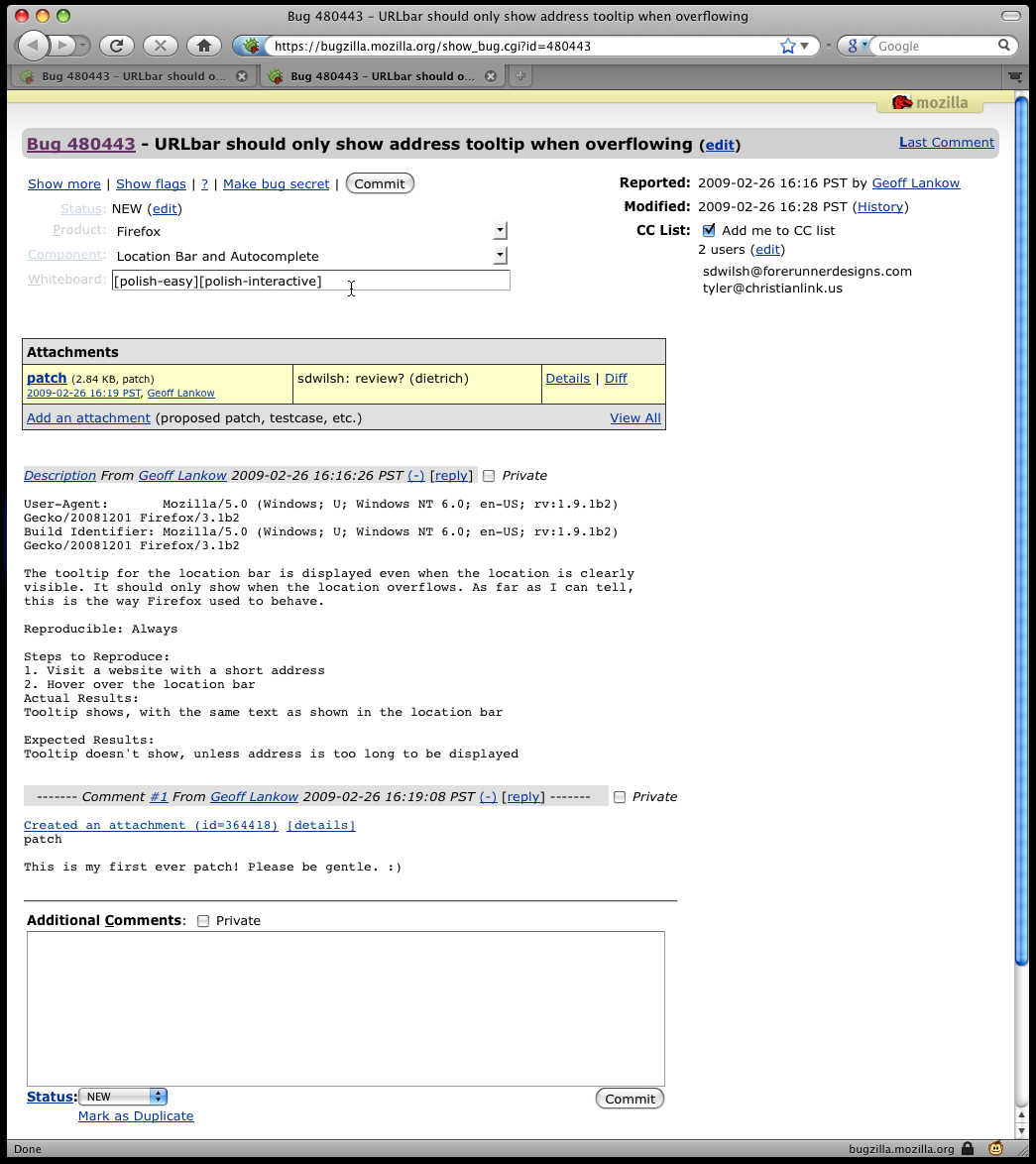
- New hotness: Bugzilla screenshot with TidyBug
{kind=link}
{kind=link}
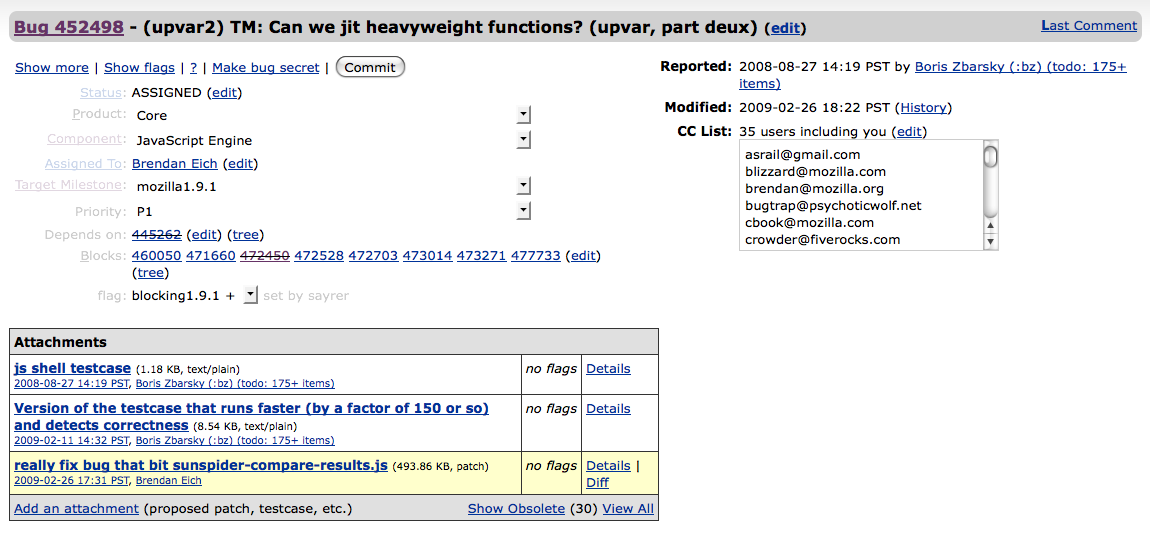
TidyBug hides empty fields, making it easier to see the fields that are populated and reducing the amount of scrolling needed to see the comments. In the example above, TidyBug removed 61% of the space above the first comment (from 985 pixels to 381 pixels). Even on busy bugs, such as upvar2, TidyBug makes the bug considerably cleaner (upvar2 screenshot).
{kind=link}
Some other things TidyBug does:
- Makes form control borders only appear on hover to reduce visual noise.
- Hides four fields that are mostly useless in bmo (version, architecture, OS, severity).
- Adds keyboard shortcuts for accessing hidden fields and several common actions.
- Clicks the "hide obsolete attachments" link for you.
Is this useful for many people? Should parts of it be uplifted into bugzilla.mozilla.org or the Bugzilla distribution? What new keyboard shortcuts or other features would you like to see?
Continuous integration at Mozilla
February 19th, 2009Mozilla's poor continuous-integration story is a major source of stress and wasted time for Mozilla developers. Andreas Gal, for example, recently lost two consecutive weekends tracking down test failures. The story is all too common:
Numb to everyday "random orange" from intermittent failures, nobody noticed the new test failures until there were multiple new test failures. Many patches occupied each regression window, due to long test cycle times, combined with many developers sharing few opportunities to land. Backing out the potentially-responsible changesets one at a time required merging and waiting through the long cycles again.
Fixing these problems will require more than incremental improvements to the Tinderbox display. It will require, at the very least, rethinking how we organize and visualize the data coming off of our build machines. It may even require changes to the way we allocate build machines and check in code.
Recent work
Over the last few months, there has been an explosion of client-side Tinderbox modifications and mashups. Here's what we have now:
- The current Tinderbox (screenshot)
- My TidyBox (screenshot)
- Justin Dolske's isthetreegreen.com (screenshot)
- Markus Stange's tinderboxpushlog (screenshot)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Other people in the Mozilla community are also interested in improving the continuous integration experience:
Why we load Tinderbox
- Developers
- Can I pull safely?
- Can I push now?
- Did I avoid breaking the tree so far?
- Can I go to sleep now?
- Sheriffs / firefighters
- Is any column missing?
- Has anything gotten slower?
- What patch caused that slowdown?
- What patch caused that test failure?
- How do I get the tree green again?
- Build engineers
- Is any machine missing or unhealthy?
- Which columns have long cycle times?
- What changes needed clobbers, indicating makefile bugs?
- Test engineers
- What tests do we have?
- What tests especially good at catching real bugs?
- What tests are we skipping?
- What tests are unreliable?
- What tests are unreasonably slow, and maybe not worth running on every build if they can't be sped up?
Tinderbox tries to answer all these questions with a single <table>. As a result, it answers none of them well.
We can design better systems for answering each of these questions, but first, I'd like to present an idea for eliminating the need to ask the questions in bold.
Try-to-push
By integrating the Try concept directly into the way we work, we can make the answer to the first four questions be always yes. Under this proposal, instead of pushing to mozilla-central, everyone pushes to a server that runs all the tests, and if the tests pass, automatically pushes the changes to mozilla-central.
Then it is always ok to pull or push, because mozilla-central is always green. If my patch breaks something, it's immediately clear that it was my patch, and I don't have to be around to back it out. I haven't wasted anyone else's time or prevented anyone else from checking in.
When there are multiple pending changesets, the automatic push should include a rebase (or hg merge, but that's probably more painful). If my patch's rebase fails, my patch doesn't end up on mozilla-central, but I claim that the occasional automatic-merge failure (requiring additional action from only one developer) is less painful than the frequent backouts we have now.
Developers should be warned up-front if a patch will require manual merging in the case that other pending changesets succeed. We should have the option of basing changes on any pending changeset in addition to mozilla-central, with the caveat that if the base fails, our changeset will not go in either. And of course, we should still be able to use Try to test a changeset without intending for it to go onto mozilla-central immediately.
Reducing cycle time
We can decrease cycle times drastically by splitting up the testing work more sanely. Instead of having four unit test machines each testing a different revision (reporting to the same column), have each machine run a quarter of the tests. When the tree is calm, results will be available in a quarter of the current amount of time; when the tree is busy, it won't be any slower.
The cycle time goal for most machines should be the same. Otherwise, we're using our resources inefficiently, because a checkin isn't done cycling until all the tests are finished. We can make exceptions for especially slow tests, such as Valgrind, static analysis, or code coverage, but these slow tests shouldn't be allowed to turn the tree orange in the same way as other tests.
Finding performance regressions
Don't make me load 53 graphs, each of which takes 6 seconds to load. Don't even make me eyeball 20 graphs. Instead, Just tell me if I make Firefox slower. (Also tell me if I increase the variance enough to make it hard to spot future slowdowns.)
Using an algorithm frees us to track more performance data, such as the time taken on of each component of SunSpider. If a patch makes a single SunSpider file 5% slower, that might be noise as part of the total SunSpider score, but obvious from looking at just that one file.
An algorithm might be slightly worse or slightly better than a human at noticing numeric changes, but it's a hell of a lot more patient.
Understanding test failures
Make it easier to see which test failed. The "short log" isn't really short, and even the summary often includes extraneous information. Just tell me which tests failed and show the log from the execution of those tests.
Ted Mielczarek is working on making Tinderboxen produce stack traces for crashes. This will make it possible to debug many issues quickly, even if we can't reproduce them. Samples for hangs would useful in the same way.
It would be great if at least some of the boxes used record-and-replay to make it possible to debug other issues, including timing issues such as non-hang timeouts and race conditions. Ideally, I'd be able to replay in a VM on my own machine and debug the issue as it unfolds.
Fixing unreliable tests
Random oranges don't have to happen. If IMVU can eliminate random oranges while testing with Internet Explorer, we can do it while testing our own products.
The first step to fixing unreliable tests is finding out which tests are unreliable. Currently, it takes a very observant sheriff to notice that the same test has failed twice in a week. Even then, we can't search to see when the test began failing, so we don't know whether to disable the test or hunt for a regressing bug. We need a searchable database of test failures.
The next step is figuring out whether the test or the code is unreliable. For now, the answer is often "mark the test as 'skip' and hope we can figure it out later", which is better than distracting everyone with random orange, but not ideal. Again, record-and-replay is probably the only reliable way to find out.
Another approach to fixing unreliable tests is to use tools designed to hunt for unreliability. Valgrind's memcheck can find the uninitialized-variable and use-after-free bugs that only lead to crashes occasionally. Valgrind's helgrind can detect many types of race conditions. Unless we build our own botnet, Valgrind tests will be too slow to be allowed to turn the tree orange, but they will give us insight into some types of bugs that cause random failures on normal test machines.
Design lunch
It's going to take a lot of work from designers and engineers to make continuous integration work well at Mozilla's new scale, but I think the potential payoff in increased developer productivity makes it worth the effort to get this stuff right.
I've only proposed ways to answer some of the questions more efficiently. I'm just an observer -- not really a Mozilla developer, and definitely not a build engineer -- so I might have missed some important points.
John O’Duinn will host a design lunch on this topic tomorrow (Thursday, February 19, noon in California).
An open letter to my email inbox
February 17th, 2009Your days of making me feel overwhelmed are numbered. "1713 messages, 221 unread" doesn't intimidate me any more. I am armed and I know enough to be dangerous.
- Gigantic todo-list text file: Processed.
- Desktop: Cleared.
- Bookmarks toolbar: Reclaimed*.
- Stacks of snail mail: Dealt with.
Inbox: You're next.
*Thanks to bug 477751 for forcing me to go through dozens of bookmarks one at a time instead of trying to sort them first.
Some file upload ideas
February 5th, 2009I didn't manage to write down or even hear all of the suggestions that came up at today's design lunch, but these ideas appealed to me:
More options for file upload controls
We could attach a menu to each <input type="file">, containing commands like:
- Paste as a text file
- Take screenshot...
- Enter path...
- Choose file...
The "Paste" option should be able to accept text, images, and files.
The "Enter path..." option should support tab completion and tell you if the file doesn't exist. It could evolve into some kind of light, cross-platform file picker.
It would be really cool if this menu could include a list of files the user has touched recently. Both Windows and Mac OS X maintain global lists of "recent documents", and we could simply show items from these lists. Alternatively, we could use file system APIs to find out whenever a new file is created, but this is tricky because we want to include files that users created manually (e.g. by saving them in an other application or by specifying them as a target on a command line) but not files that are created in the background (e.g. logs and caches).
This could be a pane instead of a normal menu, creating room for previews (e.g. for "Paste") and hints like "or you can drag files here".
Remember file upload forms
When a form contains only a file upload control, Firefox could offer to let users upload additional files without visiting the page that contains the form:
- Add an icon to the Firefox toolbar or the Mac OS X Dock that functions as a drop target.
- Add to the menu that appears when you right-click a file in Explorer or Finder.
- Add to the "Send To" menu on Windows.
- Create a special folder, where all files saved to that folder get uploaded. The site's favicon could be used as a badge making the folder look special.
- Add to the Services menu on Mac. This would let users add keyboard shortcuts to other applications to perform actions involving web sites!
- Add a shell command, allowing power users to do things like "flickr *.png" or "hg diff | pastebin".
This approach may be limited by the fact that the destination is often not a service in general, but a specific person or bug report or forum thread.
Let sites offer files
More and more of users' data is in the cloud, and this includes the things they might want to "upload" to other sites. Let users move data from one site to another without dealing with the file system.
- Whenever a site offers a download, instead of making the user pick a location, just put it in a temporary location represented as a "shelf". Once the file is on the shelf, it can be dragged to Finder or to another web site.
- Let sites offer draggable objects that represent files, so users can drag from the site directly, skipping the "shelf" step.